

Throughput Testing – Same Hypervisor and VM to VM
Just some weekend testing with two Windows 2012 R2 VM’s on the same Hypervisor and tests to see what throughput can be generated using the Microsoft NTttcp utility…
These are truly science experiments given there is no application that runs with a single IP stream between internal VM’s (such as App to DB) or to external users… By definition, every user connection would be a unique IP stream.
Overall, pretty straight forward to achieve multi gigabit performance out of the box and with more simultaneous streams, the aggregate bandwidth could easily exceed physical wire speed of the server.
The 64KB window is also a worst case scenario and certainly bigger window sizes can assist in improve throughput…
NTttcp 5.28 can be downloaded from Microsoft. The command line configuration I used on client and sever is:
NTttcp.exe -s -wu 5 -cd 5 -m 1,*,<server ip> -l 64k -t 60 -sb 1024k -rb 1024k (Client)
NTttcp.exe -r -wu 5 -cd 5 -m 1,*,<self ip> -l 64k -t 60 -sb 1024k -rb 1024k (Server)
Hypervisor is a 2.1 GHz 2 Socket 6 Core SuperMicro running ESXi 5.5 and each VM is 6 cores/8 GB RAM…

The server has 10 GbE but tests below are internal to the hypervisor so no external network testing just yet…
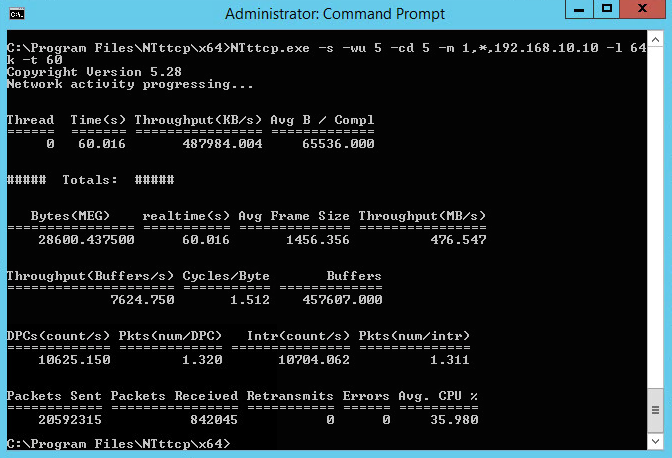
Here is an example of one of my initial tests using a Single Stream – 64K Window – Default Send and Receive Buffers – 1500 Byte MTU and 476 MB/s or 3.7 Gb/s. Not too bad out of the box…
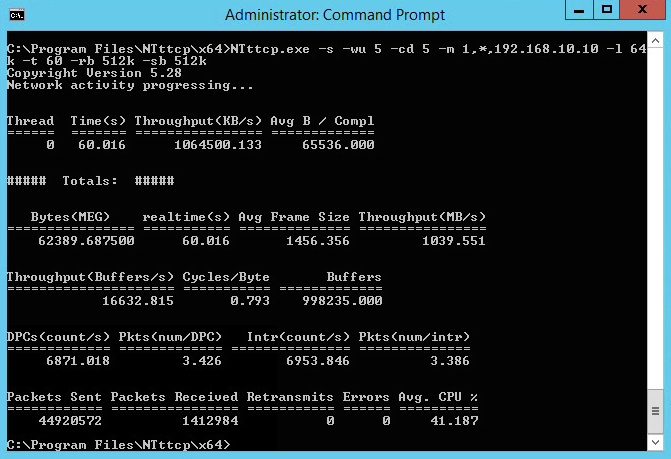
Same configuration but increasing buffer… So approaching “wire” speed but VM’s are on the same host so no wire to worry about:
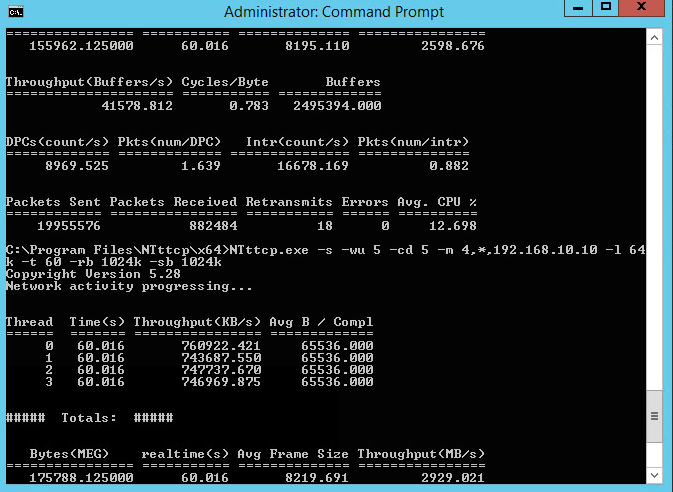
Having a little fun now and this configuration is 4 streams, OS RSS enabled and Jumbo Frames with a result of 2929 MB/s or 22 Gb/s. Certainly validates the need for Jumbo Frames and VM placement (Network DRS) to take advantage of kernel network IO capabilities.
Note the retransmissions at these speeds and I need to do some more work to see how retransmits can be reduced.
What was interesting is the VM optimizations (interrupt coalescing etc) did not appear to have any noticeable impact but I believe this is because all of the above is in software (VM to VM) and as such, is not touching any interrupt driven physical hardware.
The following is a summary of the tests I performed and probably the most interesting aspect of testing is the impact of send and receive buffers – too large and performance falls off dramatically, and too small, larger results (range) between tests – CPU seems to be the limiting factor and I plan to do some more tests around this.
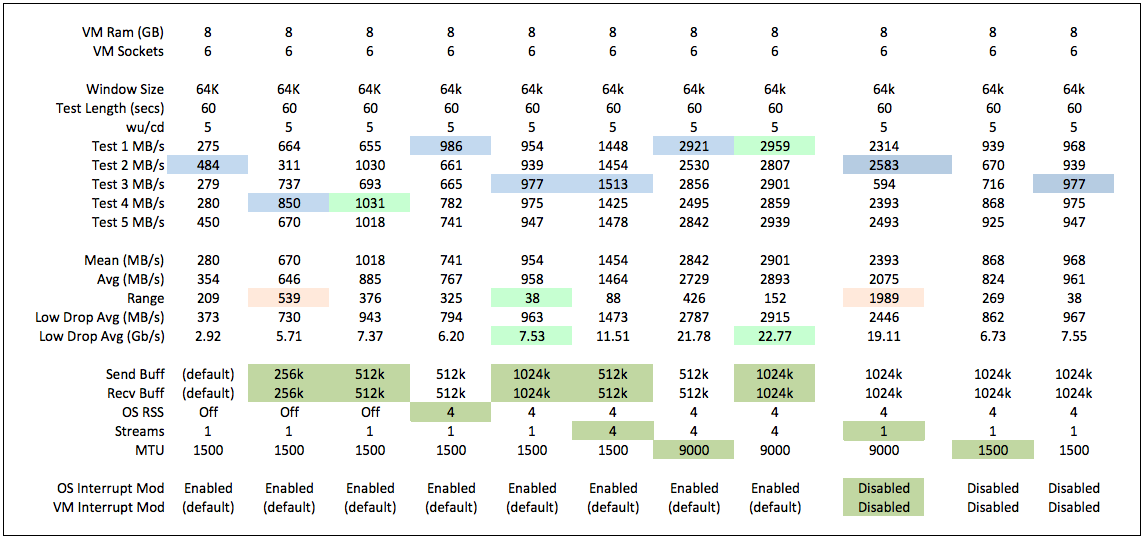
Link to above excel results file.
In summary VM’s need the following to optimize network IO:
- CPU – 4 Streams will use most of the VM CPU (but for the purposes of the test, passing an incredible amount of data)
- Multiple Streams
- OS Receive Side Scaling
- Send and Receive Buffers
- Jumbo Frames
I would welcome any feedback on these tests, and the next step is the same tests between separate hypervisors 😉
did you test with vmxnet3, e1000e, or e1000? Did you encounter CPU bottlenecks anywhere?
All testing was performed using the VMXNET3 adapter due to numerous KB’s which speak to superior capabilities of the VMXNET3 adapter. Earlier testing on E1000 really did not show a huge difference in performance but it will be easy for me to retest for you. CPU is definitely a bottleneck and 4 steams pushed VM’s to max CPU performing at 10Gb/s combined throughput VM to VM with 1500 MTU, and performing at 20Gbp/s combined throughput VM to VM with 9000 MTU. I am optimistic NIC hardware offload capabilities when testing Hypervisor VM to Hypervisor VM should reduce individual VM CPU.